Breaking News: Multilingual AI Cognitive Screening for the Chinese-Speaking Community
Other Articles

Advancing Early Detection Through Speech-Based Biomarkers in English and Chinese
Study conducted by Prof. Hualou LIANG and his research team
and his research team

Cognitive impairment, including mild cognitive impairment (MCI) and Alzheimer's disease, is a growing challenge in ageing societies. Early detection is crucial, as timely intervention can improve care planning, monitoring and quality of life. Yet cognitive decline is often identified only after symptoms have become more pronounced, limiting opportunities for support.
Current diagnostic tools remain imperfect. Screening tests such as the Mini Mental State Examination (MMSE) can be influenced by language, education and culture, while neuroimaging and specialist assessments are costly and not always accessible. This has made speech an increasingly attractive digital biomarker. Because speech reflects multiple cognitive processes, subtle changes in fluency, pausing and vocal delivery may provide a non-invasive and scalable route to earlier detection.
Prof. Hualou LIANG, Interim Head (Artificial Intelligence and the Humanities) and Chair Professor of Neuroscience and Artificial Intelligence of the Department of Language Science and Technology and the Department of Data Science and Artificial Intelligence at The Hong Kong Polytechnic University, and his research team advance this line of work in a multilingual context, showing how AI-based speech analysis may support more practical and inclusive cognitive screening.
Their study was conducted as part of the INTERSPEECH 2024 TAUKADIAL Challenge, a task focused on detecting mild cognitive impairment and predicting cognitive scores from spontaneous speech, with the results presented in Brain Sciences [1]. The significance of this challenge lies in its multilingual scope. Previous work in speech-based dementia research has been heavily focused on English datasets, leaving uncertain whether reported findings can generalise across languages and cultures. This study directly addresses the gap by examining both English and Mandarin Chinese speech, thereby making a meaningful contribution to the development of more globally relevant cognitive assessment tools.
The dataset was collected through picture description tasks, a well-established format in cognitive assessment because it elicits spontaneous yet structured speech. Participants were required to describe three pictures. Across both languages, the study included 169 participants, comprising individuals with MCI and those with normal cognition, balanced by age and sex to reduce demographic bias. The study addressed two tasks. The first was MCI classification, in which the model distinguished cognitively healthy speakers from those with mild cognitive impairment. The second was MMSE score prediction, a regression task aimed at estimating an individual’s cognitive score directly from their speech. Together, these tasks reflect the need for both screening and monitoring, suggesting that speech-based AI could support not only binary risk detection but also more continuous assessment of cognitive status.
At the centre of the approach is Whisper, specifically whisper-large-v3, used as a foundation model for acoustic feature extraction. This is a notable methodological choice. Rather than relying on traditional handcrafted features alone, the team used Whisper's encoder to generate 1280-dimensional embeddings from the speech signal. These embeddings provide a rich learned representation of the audio recording and reflect the growing importance of foundation models in speech technology. Their use here signals an important shift in cognitive assessment research: from manually engineered markers towards large-scale, transferable representations capable of capturing subtle acoustic patterns across languages.
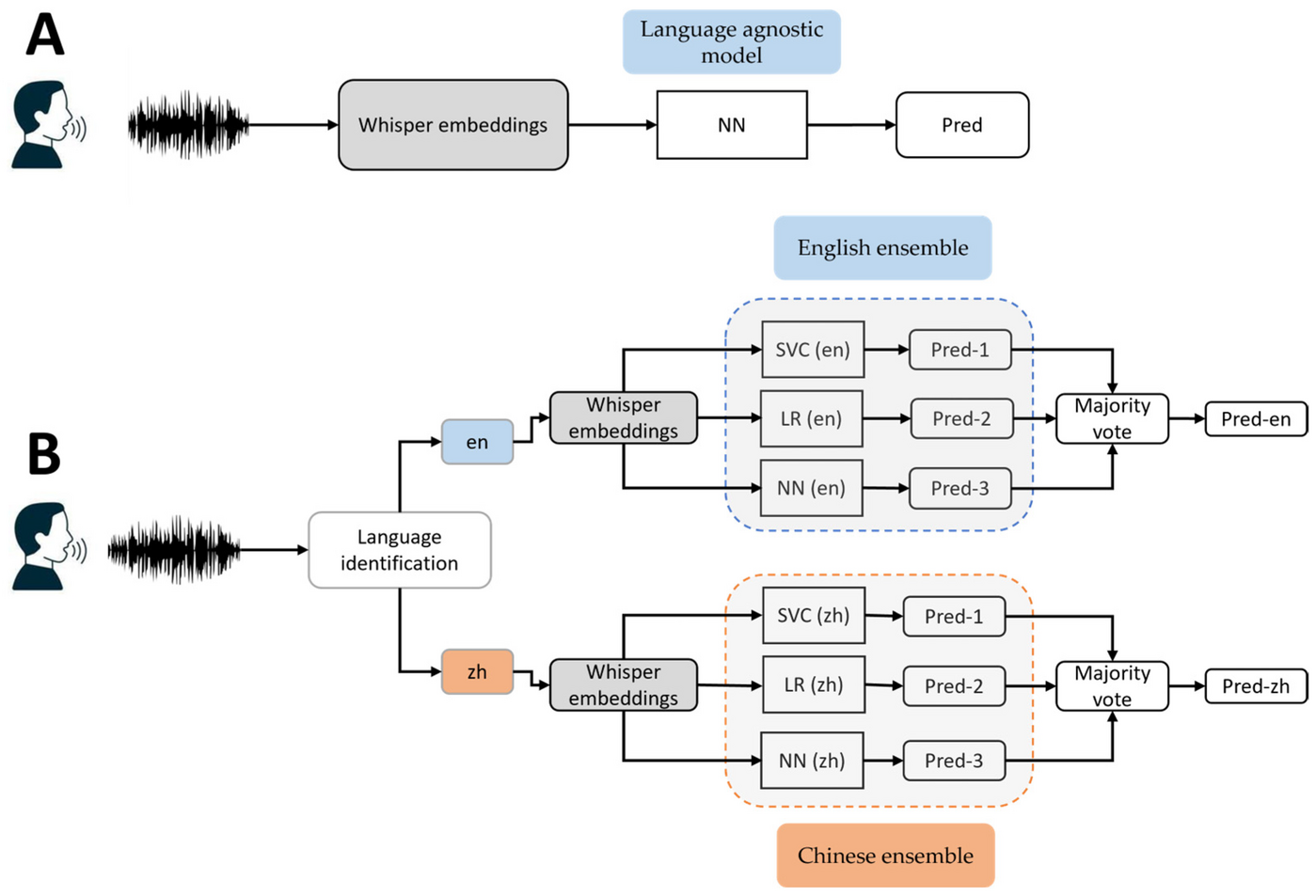
Figure 1. Diagram of two modelling pipelines: (A) language-agnostic model, and (B) language-specific ensemble model
The study compared two modelling pipelines (Figure 1). The first was a language-agnostic baseline. In this model, Whisper embeddings were extracted, normalised and passed directly into a classifier such as a neural network, without any explicit language identification. This baseline is conceptually attractive because it tests whether a single multilingual system can capture common acoustic indicators of cognitive decline across English and Chinese.
The second pipeline was a language-specific ensemble model. Here, the language of each recording was first identified, after which the speech was processed through a language-tailored modelling route. The most interesting part of this design is the way it incorporated the three picture-description tasks. Rather than treating all speech prompts as interchangeable, the team trained models on two tasks and tested on the third, repeating this across all task combinations. This produced three predictions per participant. For MCI classification, the final decision was obtained through majority voting; for MMSE prediction, the outputs were averaged.
For MCI classification, the ensemble included a support vector classifier, logistic regression and a neural network. For MMSE score prediction, the team used Ridge Regression and a neural network. The study also experimented with linguistic text embeddings derived from Whisper transcriptions, using strong language-specific embedding models for English and Chinese.
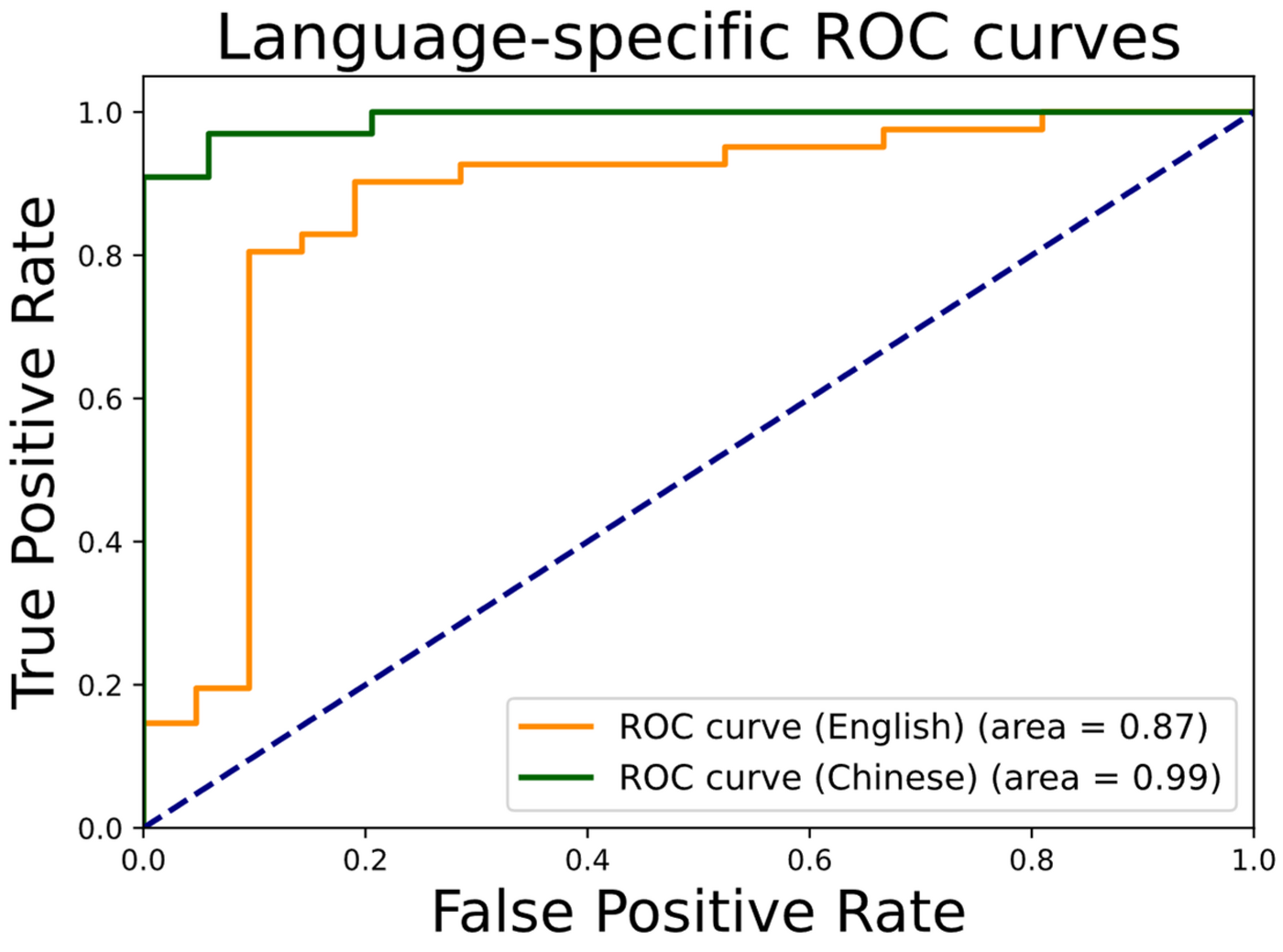
Figure 2. Receiver operating characteristic curves of the language-specific model for Chinese and English datasets
The results strongly favour the language-specific approach. On the unseen test set for MCI classification, the language-specific ensemble achieved an unweighted average recall of 81.83%, compared with 61.2% for the language-agnostic baseline. This is a substantial improvement and indicates that language-specific nuance remains important even when using a powerful multilingual foundation model. The study also reported strong receiver operating characteristic performance (Figure 2), with AUC values of 0.87 for English and 0.99 for Chinese, demonstrating high discriminatory ability within each language.
A similar pattern was found in MMSE score prediction. The language-specific ensemble outperformed the language-agnostic model and achieved an RMSE of 1.196, a strong result given the challenge of estimating cognitive scores from spontaneous speech alone. This suggests that speech-based AI may have value not only for screening but also for more fine-grained, quantitative tracking of cognitive status.
One of the most revealing elements of the study is its examination of between-language transfer. When models trained on one language were applied to the other, performance declined markedly. This finding has important implications. It shows that, although Whisper provides multilingual embeddings, the speech signatures of cognitive impairment are not fully language-independent. They remain shaped by phonetic, linguistic and cultural factors. Multilingual capability does not remove the need for localisation. On the contrary, effective deployment may depend on combining shared representation learning with language-specific adaptation.
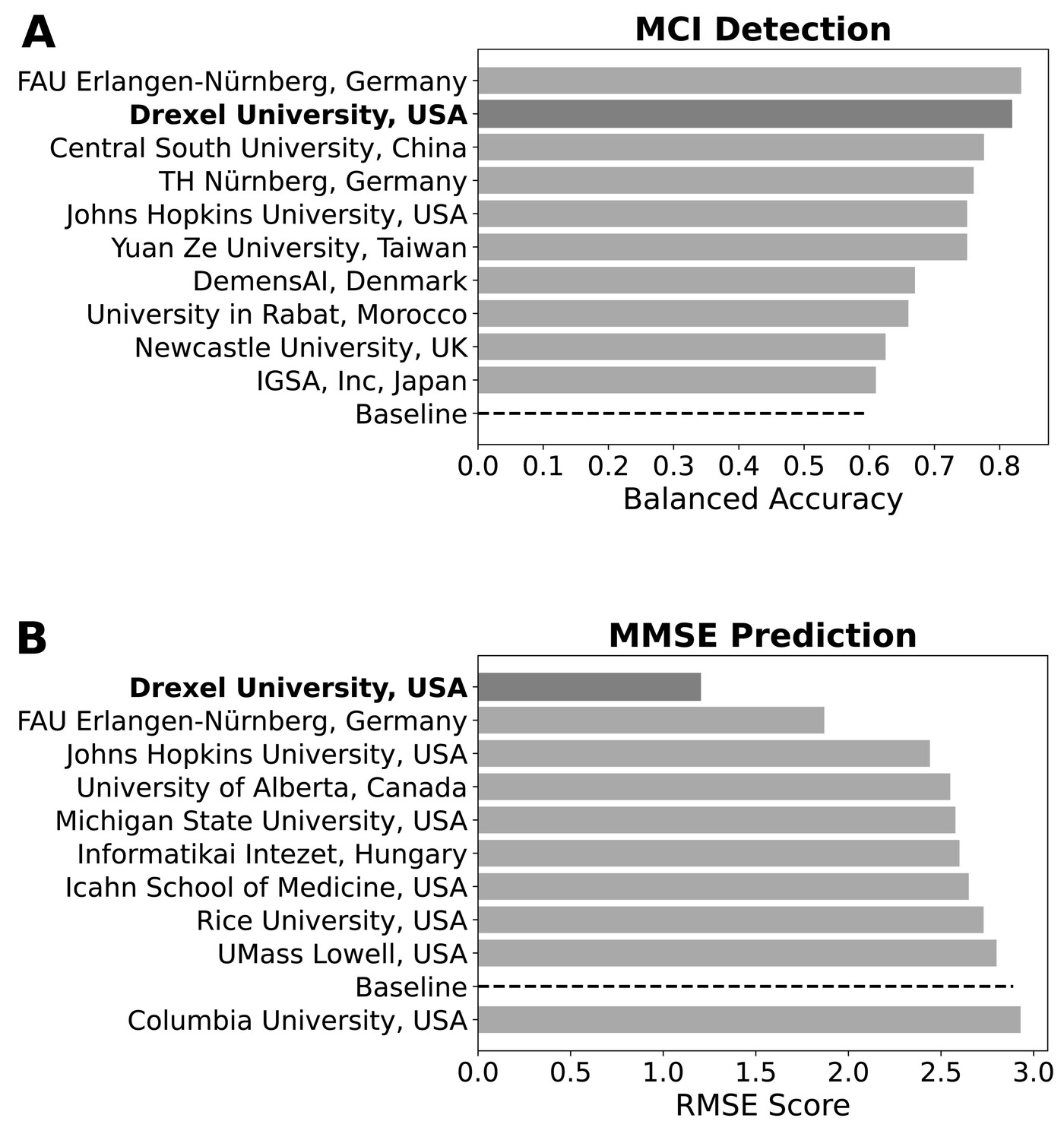
Figure 3. Rankings of the top ten teams and the baseline method in the challenge: (A) the model of Prof. Liang’s team ranked second (dark grey) for the MCI classification task; and (B) it ranked first (dark grey) for the MMSE cognitive score prediction task
The practical significance of this study is reinforced by its standing in the challenge itself. Among all participating teams in the INTERSPEECH 2024 TAUKADIAL Challenge, the proposed model ranked second for MCI classification and first for MMSE prediction (Figure 3). These rankings are impressive not merely as competition results, but because they demonstrate that a relatively streamlined system based on spontaneous speech and acoustic embeddings can achieve state-of-the-art performance against an international benchmark. The work therefore strengthens the case for speech as a clinically useful, low-burden digital biomarker.
More broadly, the study points towards a future in which cognitive screening may become more frequent, more remote and more inclusive. It helps define the next stage of research, including multimodal approaches that combine acoustic, linguistic and possibly non-verbal behavioural cues.
INTERSPEECH 2024 is a major international conference in speech science and technology, organised by the International Speech Communication Association. It brings together researchers and industry experts working on speech processing, artificial intelligence, spoken language systems and related applications. In addition to its main research programme, the conference is known for its challenge tracks, which provide shared tasks and benchmark datasets to advance the field through transparent comparison. One of these was the TAUKADIAL Challenge, focused on multilingual detection of cognitive impairment and cognitive score prediction from spontaneous speech.
Prof. Liang has been recognised by Stanford University as one of the top 2% most-cited scientists worldwide (career-long) in the field of artificial intelligence and image processing for six consecutive years, from 2020 to 2025. His research interests focus on neural data science, machine learning and biomedical natural language processing. He is known for pioneering the application of causal functional connectivity measures, particularly Granger causality, to the analysis of complex, high-dimensional neuroscience data. In recognition of his significant contributions to the development of advanced signal processing methods for the analysis of functional brain networks, he is an elected Fellow of the American Institute for Medical Biological Engineering. Prof. Liang is also committed to building collaboration with professionals in advancing research of spoken language processing for healthcare and the development of large language models for dementia prediction. His recent research has been featured in media outlets that include Psychology Today, Jerusalem Post, The New York Times and IEEE Spectrum.
| References |
|---|
[1] Agbavor, F.; Liang, H. Multilingual Prediction of Cognitive Impairment with Large Language Models and Speech Analysis, Brain Sciences, 2024, 14, 1292. https://doi.org/10.3390/brainsci14121292
 | Prof. Hualou LIANG Interim Head (Artificial Intelligence and the Humanities) |


