First Large-Scale Discovery of Gas-Wasting Code Smells in Smart Contracts
Other Articles

An AI Approach to Identifying and Reducing Gas Inefficiencies in Ethereum Smart Contracts with GPT-4
Study conducted by Prof. Xiao Ming WU  and a research team led by Prof. Daniel Xiaopu LUO
and a research team led by Prof. Daniel Xiaopu LUO

Smart contracts have swiftly established themselves as a core component of decentralised applications, ushering in a new era of financial innovation on blockchain platforms. These self-executing programmes, most notably on Ethereum, facilitate trust-free, transparent and immutable transactions without the need for intermediaries. However, the very features that make smart contracts so powerful also introduce unique challenges—the efficient use of computational resources, measured in 'gas'. As the adoption of smart contracts accelerates, the importance of optimising gas consumption has never been greater, both for economic sustainability and for the scalability of blockchain ecosystems.
Gas is the unit of computational cost in Ethereum, representing the resources required to execute operations within the Ethereum Virtual Machine (EVM). Every function call, storage operation or event emission in a smart contract incurs a gas fee, which is ultimately paid by users in Ether. This mechanism is essential for preventing abuse and ensuring fair resource allocation across the network.
However, the complexity of gas pricing, combined with the abstraction provided by high-level languages like Solidity, often leads developers to inadvertently write codes that are inefficient in terms of gas usage. These inefficiencies, known as 'gas-wasting code smells', can significantly inflate the cost of deploying and interacting with smart contracts, undermining their utility and accessibility.
The identification and remediation of gas-wasting code smells is therefore a matter of both academic and practical significance. Traditionally, this process has relied on manual code review by domain experts, a time-consuming and error-prone endeavour, especially as the volume and complexity of smart contracts continue to grow. While previous research has catalogued certain gas-wasting patterns, the field has lacked a systematic, scalable approach to uncovering new and context-specific inefficiencies at the source code level.
To address the above challenges, Prof. Xiao Ming WU, Associate Professor of the Department of Data Science and Artificial Intelligence at The Hong Kong Polytechnic University, worked with a research team led by Prof. Daniel Xiaopu LUO to introduce a pioneering methodology: the integration of Large Language Models (LLMs), specifically GPT-4, into the pipeline for discovering gas-wasting code smells in Ethereum smart contracts. This marks the first large-scale, automated effort to systematically identify such inefficiencies, resulting in the largest and most novel set of gas-wasting code smells reported to date. The results of their study have been published in IEEE Transactions on Software Engineering [1].
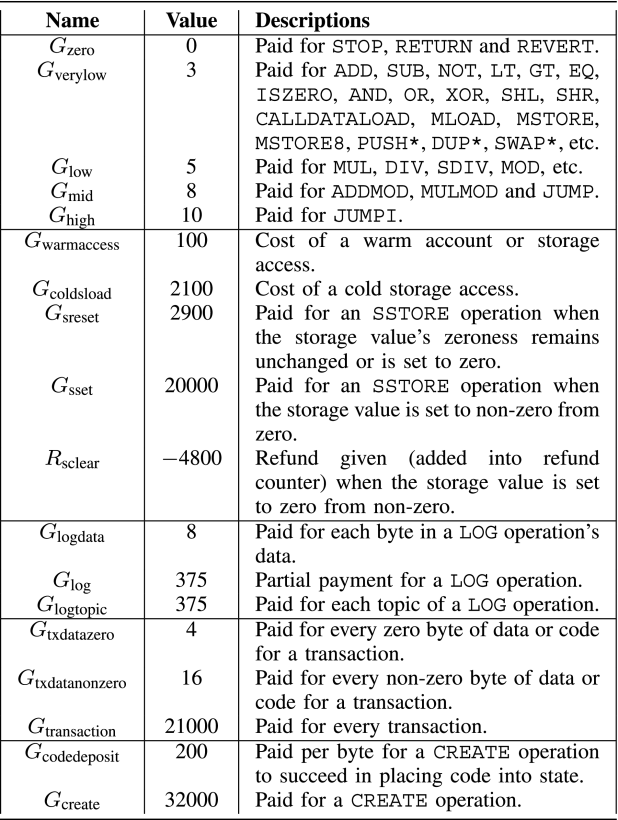
Table 1. An example gas fee schedule
To appreciate the significance of this research, it is important to understand the mechanics of gas fees in Ethereum. The EVM operates as a transaction-based state machine, where each transaction triggers a state transition and executes a series of bytecode instructions. Each instruction has a predefined gas cost, reflecting its computational or storage demands. For example, operations that modify blockchain storage (such as SSTORE) are considerably more expensive than those that merely manipulate memory or perform arithmetic (Table 1). This pricing structure incentivises developers to write efficient code, but it also introduces a steep learning curve. Many developers, especially those new to blockchain, are unaware of the subtle ways in which conventional coding practices can lead to excessive gas consumption. The result is a proliferation of contracts that, while functionally correct, are economically suboptimal.
The research tackles this challenge by leveraging the capabilities of GPT-4 to automate the most labour-intensive aspects of code smell identification. The core of Prof. Wu's approach is a six-step pipeline (Figure 1), meticulously designed to balance the strengths and limitations of LLMs with the rigour of human verification.
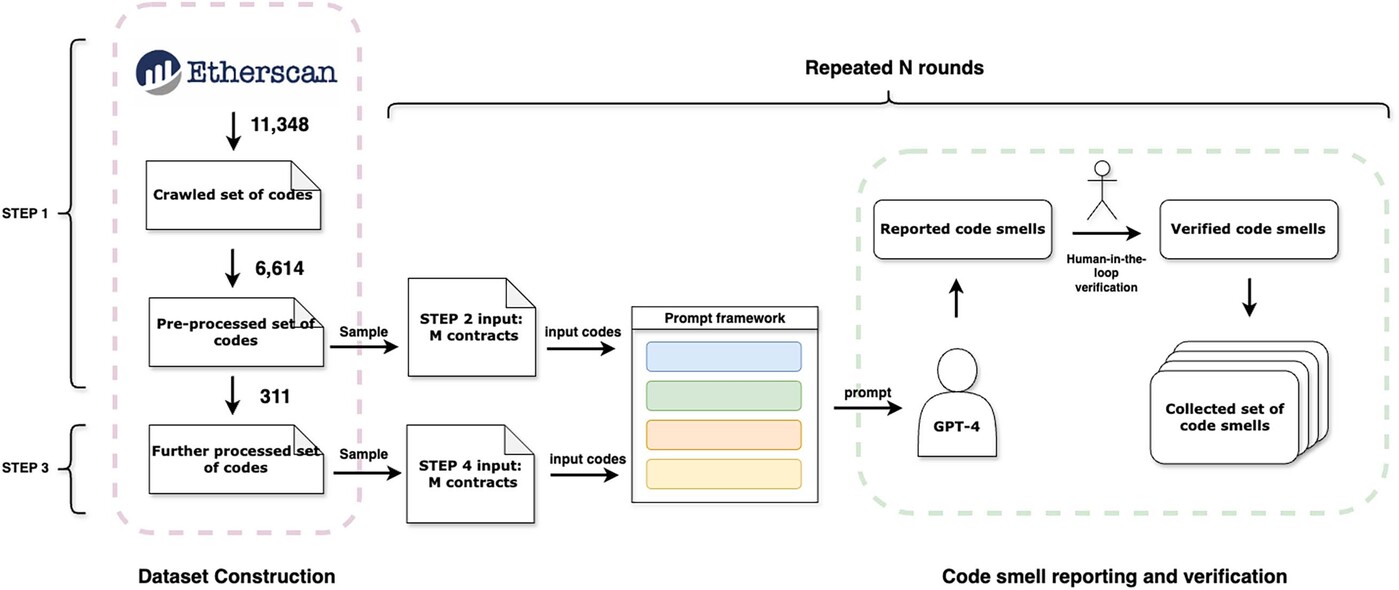
Figure 1. Illustration of the pipeline.
The first step in the pipeline is the collection and pre-processing of a comprehensive dataset of smart contracts. The team began by crawling 11,348 recently verified Solidity contracts from Etherscan, focusing on those written with up-to-date compiler versions to ensure relevance. To maximise diversity and reduce redundancy, it applied hash-based deduplication, filtered out contracts with fewer than 100 lines of code, and prioritised contracts with unique and complex functions. This process distilled the dataset to a manageable yet representative subset with 6,614 contracts, optimised for the discovery of varied gas-wasting patterns.
The second step involves the preliminary identification and categorisation of code smells. Here, the team employed the initial prompt framework to guide GPT-4 in analysing selected contract segments. Due to input length constraints, it experimented with different strategies for presenting code to the model, such as removing trivial functions and focusing on longer, more complex code blocks. The outputs from GPT-4 were then manually verified by experienced blockchain developers, who assessed the validity and novelty of each reported code smell.
In the third step, the team refined the dataset further based on insights gained from the initial rounds of analysis. Contracts were filtered to ensure a high degree of functional and syntactic diversity, reducing the likelihood of repeatedly encountering the same patterns. This step also involved the identification of 'salient' functions—those that are both unique and complex—thereby increasing the probability of uncovering new and interesting code smells. During this process, 311 contracts were eventually sorted out.
The fourth step focused on the automation and optimisation of code smell discovery. Building on feedback from earlier rounds, the team developed a method for constructing input code blocks that prioritised longer functions and preserved contextual information, while eliminating unrelated components such as comments and imports. This approach, inspired by established refactoring techniques, helps scale the analysis and improve the quality of GPT-4 outputs.
The fifth step was an ablation study, designed to evaluate the contribution of each component of the methodology. By systematically removing elements such as few-shot examples, chain-of-thought prompting and self-inspection from the prompt framework, the team assessed their impact on the diversity and accuracy of discovered code smells. This analysis provided valuable insights into the optimal configuration for LLM-driven code analysis.
The sixth and final step was a comprehensive quality assessment. The set of identified code smells was compared against existing studies to evaluate novelty, and the actual gas savings achieved by applying the recommended optimisations to real-world contracts were measured. The results were striking: this approach found 26 distinct gas-wasting code smells, 13 of which were previously unreported. On average, these optimisations reduced deployment costs by over 10% and message call costs by more than 21%, demonstrating both the novelty and practical impact of the findings.
Central to the success of the pipeline is the design of the prompt framework used to interact with GPT-4. This framework comprises four key blocks (Figure 2), each serving a distinct purpose in eliciting high-quality, reliable outputs from the model.
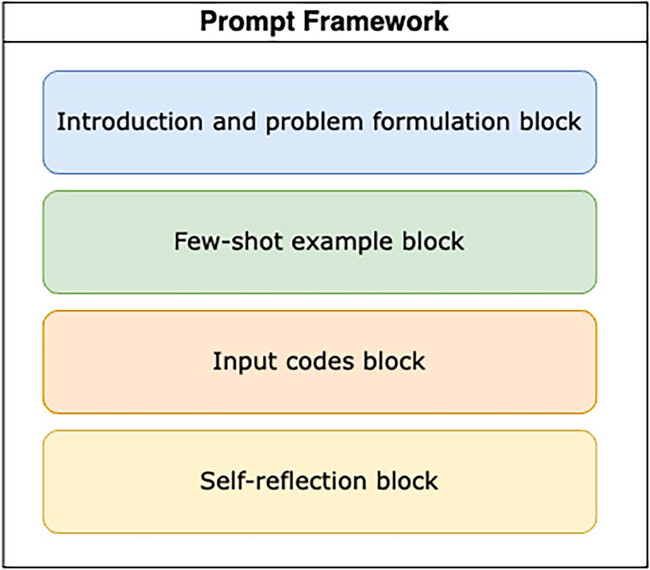
Figure 2. The four key blocks of the prompt framework.
The first block is the introduction and problem formulation. This section provides GPT-4 with a clear explanation of the task, including definitions of key concepts such as gas, code smells and the specific objectives of the analysis. By articulating the problem from multiple perspectives and repeating critical instructions, the team minimises the risk of ambiguity or misunderstanding, which are common pitfalls in LLM-driven tasks.
The second block consists of few-shot examples. Here, they present GPT-4 with concrete instances of gas-wasting code smells, drawn from both the existing literature and the team's own discoveries. This technique, known as few-shot learning, enables the model to generalise from examples and improves its ability to identify similar patterns in new codes.
The third block is the input codes block, which contains the actual smart contract code to be analysed. Careful selection and structuring of this input are crucial, as this determines the context and complexity of the analysis. By focusing on non-trivial, context-rich code segments, the team enhances the likelihood of finding subtle and previously overlooked inefficiencies.
The fourth and final block is self-inspection. In this section, GPT-4 is prompted to reflect on its own reasoning process, assess the trade-offs associated with each reported code smell such as impacts on readability, maintainability and security, and identify any ambiguities or challenges encountered during the task. This reflective approach not only improves the quality of the outputs, but also provides valuable feedback for further refinement of the prompt framework.
The evaluation of the methodology demonstrates its effectiveness and extensibility. This LLM-assisted pipeline not only identified the largest and most novel set of gas-wasting code smells to date, but also delivered substantial gas savings in practical deployments. The approach proved adaptable to other programming languages such as Vyper, to new EVM features including those proposed in recent Ethereum Improvement Proposals, and to alternative LLMs like Claude-3, underscoring its potential for broad application across the blockchain ecosystem.
In summary, this research represents a significant advance in the automated analysis and optimisation of smart contracts. By harnessing the power of LLMs, the team has transformed the traditionally manual process of code smell identification into a scalable, systematic and highly effective methodology. As smart contracts continue to proliferate and evolve, such tools will be indispensable for ensuring the efficiency, affordability and sustainability of decentralised applications in the FinTech landscape.
Prof. Wu was recognised by Stanford University as one of the top 2% most-cited scientists worldwide (single-year) in the field of information and communication technologies for two consecutive years, from 2024 to 2025. She has a broad interest in the field of AI, with research endeavours in retrieval and recommendation. Her recent research focuses on the development and applications of conversational, generative and multimodal AI.
| References |
|---|
[1] Jiang, J., Li, Z., Qin, H., Jiang, M., Luo, X. & Wu, X. (2025) Unearthing Gas-Wasting Code Smells in Smart Contracts with Large Language Models, IEEE Transactions on Software Engineering, vol. 51, no. 4, pp. 879-903, April 2025, doi: 10.1109/TSE.2024.3491578.
 | Prof. Xiao Ming WU |


