
A novel multimodal agent advances understanding of long video

Understanding long videos is a significant challenge for AI models. A PolyU research team has developed VideoMind, an AI video-language agent that mimics human thought processes to improve reasoning and question-answering capabilities. The innovative Chain-of-Low-Rank Adaptation (LoRA) strategy also reduces the demand for computational resources and power, advancing generative AI in video analysis.
Role-based workflow improves video understanding
Videos longer than 15 minutes often contain complex information, including sequences of events, causality and scene transitions. To understand this content, AI must identify objects and track their changes over time. However, the extensive visual data requires substantial computational resources, creating challenges for traditional AI models.
To address these challenges, Professor Chen Changwen, Interim Dean of the Faculty of Computer and Mathematical Sciences and Chair Professor of Visual Computing, led a research team that developed a framework incorporating a role-based workflow inspired by human cognitive processes. This approach enhances temporal reasoning and addresses a significant obstacle in AI video understanding.
The four key roles for VideoMind are:
Planner
Coordinating all other roles for each query
Grounder
Localising and retrieving moments
Verifier
Validating the information accuracy of the retrieved moments and selecting the most reliable one
Answerer
Generating the query-aware answer
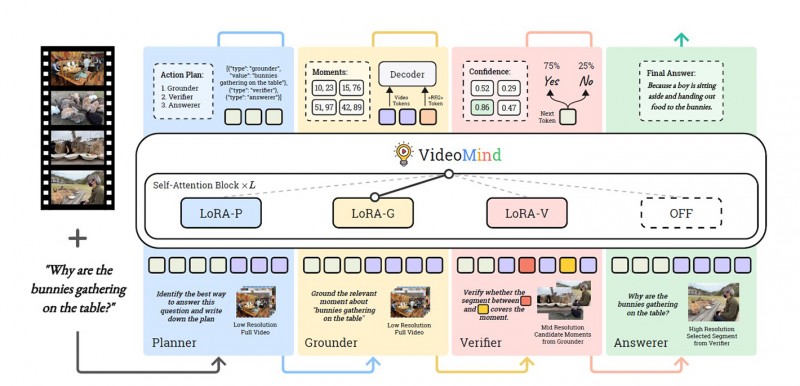
In designing VideoMind, the researchers drew inspiration from human-like video understanding processes and incorporated four roles into the framework.
Chain-of-LoRA enhances performance
A core innovation of VideoMind is its Chain-of-LoRA strategy. LoRA is a modern fine-tuning technique that adapts AI models for specific tasks without full retraining. The team’s approach involves four lightweight LoRA adapters within a unified model, enabling dynamic role-switching during inference. This eliminates the need for multiple models, improving efficiency and reducing costs.
VideoMind is available as open source on GitHub and Hugging Face, with experimental results demonstrating its effectiveness across 14 benchmarks. The framework outperformed state-of-the-art AI models, including GPT-4o and Gemini 1.5 Pro, particularly in tasks involving videos averaging 27 minutes in length. Remarkably, the smaller two billion (2B) parameter version of VideoMind matched the performance of many larger seven billion (7B) models.
Emulating human efficiency
Humans switch between different thinking modes to understand videos, with the brain consuming about 25 watts of power – roughly a million times less than a supercomputer with equivalent capabilities. Professor Chen explained, “Inspired by this, we designed the role-based workflow that allows AI to understand videos like humans while leveraging the chain-of-LoRA strategy to minimise the need for computing power and memory in this process.”
The VideoMind framework, built on the open-source Qwen2-VL model and enhanced with optimisation tools, lowers technological costs and deployment thresholds. It offers a viable solution to the challenge of reducing power consumption in AI models, which are often constrained by insufficient computing power and high energy demands.
Professor Chen added, “VideoMind not only overcomes the performance limitations of AI models in video processing, but also serves as a modular, scalable and interpretable multimodal reasoning framework. We envision that it will expand the application of generative AI to various areas, such as intelligent surveillance, sports and entertainment video analysis, video search engines and more.”



{kind=link}