LLM with Ultra-Low Resource and Strong Reasoning Capability
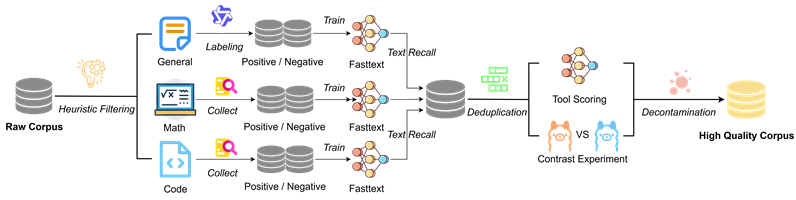
High-quality pre-training data forms the foundation of a model's core capabilities and is essential for strong reasoning performance. Our research focuses on systematic data processing pipelines that include heuristic filtering, positive/negative sampling, and advanced post-training techniques. Through instruction evolution, response generation, and preference optimization, we effectively activate the model's potential and enhance its reasoning performance.
• InfiR-1B Instruct outperforms larger Qwen models by 12.9% on MATH benchmark
• InfiR-1B Base surpasses larger Qwen models by 6.9% on HumanEval benchmark
Supervised Fine-Tuning Data Pipeline
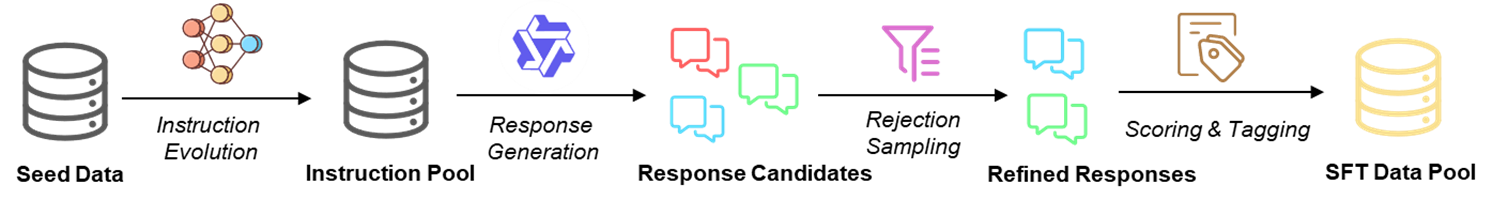
High Quality Corpus Data Processing
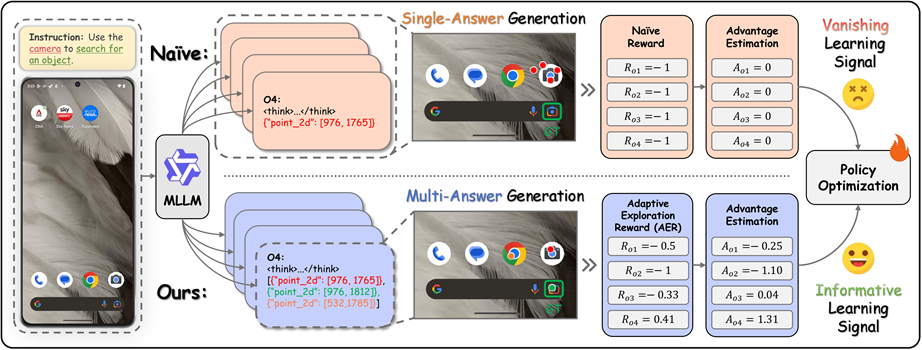
Multi-Answer Generation with Adaptive Exploration Reward for Enhanced Learning
MLLM with Ultra-Low Resource and Strong Multimodal Reasoning
InfiGUI-G1 addresses critical challenges in GUI interaction through grounding enhanced reinforcement learning. Our approach tackles both spatial and semantic alignment issues, enabling precise localization and interaction with GUI elements. The system demonstrates exceptional performance on the ScreenSpot-Pro benchmark, achieving superior results across multiple categories including CAD, Creative, Scientific, Office, and OS tasks.
• Advanced spatial alignment for precise GUI element interaction
• Superior semantic understanding for complex interface navigation
• Leading performance on ScreenSpot-Pro benchmark across all categories
Ultra-Efficient Low-Bit LLMs: Train & Development
Our breakthrough research addresses the critical challenge of performance degradation in quantized models, particularly for reasoning-related tasks. By decomposing reasoning ability into finer dimensions, we construct specialized datasets that enable rapid recovery of reasoning capabilities on mathematical tasks using only one-fourth of the original memory.
• Advanced spatial alignment for precise GUI element interaction
• Superior semantic understanding for complex interface navigation
• Leading performance on ScreenSpot-Pro benchmark across all categories
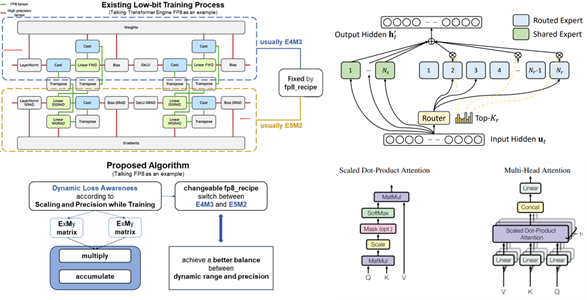
Dynamic Loss Awareness Algorithm for FP8 Training with Improved Precision Balance
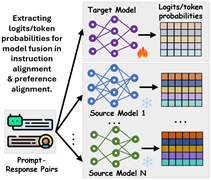
Stage 1: Knowledge Extraction - Extracting logits/token probabilities from multiple source models
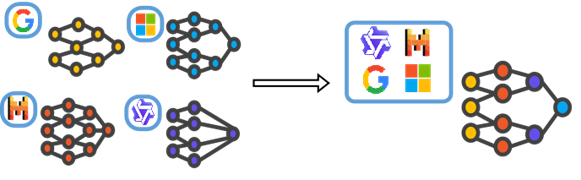
Stage 2: Knowledge Alignment - Cross-institutional model fusion and collaboration
Unconstrained Model Fusion for Enhanced LLM Reasoning
InfiFusion revolutionizes model collaboration through a unified framework that enables knowledge transfer across different domains and model scales. Our approach supports multiple fusion strategies including logits distillation, data distillation, preference distillation, and weight fusion. By employing Pairwise and Unified Fusion strategies, we achieve superior performance at only 1/10,000th the computational cost of traditional training methods.
• Only 160 GPU hours merged 4 models, boosting reasoning by 10%+
Model Fusion via Preference Optimization for Enhanced LLM Reasoning
Advanced preference optimization techniques enable seamless integration of multiple specialized models, creating unified systems with enhanced reasoning capabilities. Our approach leverages sophisticated algorithms to balance different model strengths while maintaining computational efficiency and performance consistency across diverse reasoning tasks.
• Low-Resource Model Fusion, Outperforms Peer Models with Equal Size
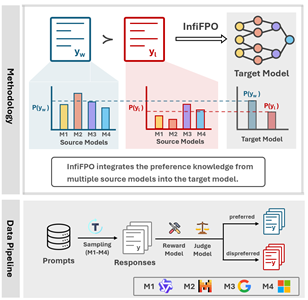
InfiFPO Methodology: Preference Knowledge Integration and Data Pipeline
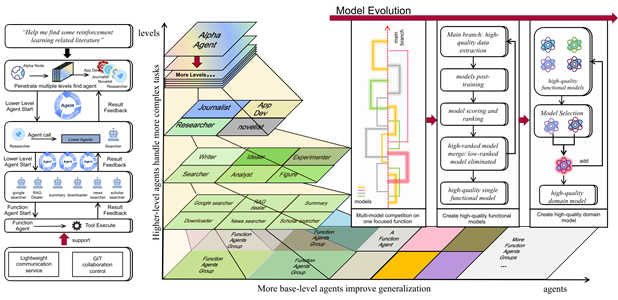
Hierarchical Agent Architecture with Multi-Level Task Handling and Systematic Model Evolution
Agentic AI
Our autonomous AI agent systems demonstrate sophisticated decision-making capabilities through advanced architectural designs. These systems integrate multiple reasoning modules, enabling complex task execution with minimal human intervention while maintaining high performance standards across diverse application domains.
• ReAct-style general agent frameworks that solve complex problems through "reasoning-action" loops
• AutoGPT attempting fully autonomous task execution
• Multi-agent systems like Multi-Agent Debate that improve decision quality through collaborative agents
• RAG-based knowledge-enhanced agents trying to compensate for model limitations with external knowledge bases
AoE: Angle-Optimized Embeddings for Semantic Textual Similarity
Text embedding plays a pivotal role in semantic textual similarity and information retrieval tasks, yet traditional methods relying on cosine-based similarity suffer from inherent limitations in capturing fine-grained semantic relationships. To address this, we propose AnglE (Angle-optimized Embeddings), a novel text embedding approach that optimizes angle differences in complex space instead of relying on cosine similarity.
• 35 million total downloads
• 700,000 monthly downloads
• Angle optimization in complex space for superior embeddings
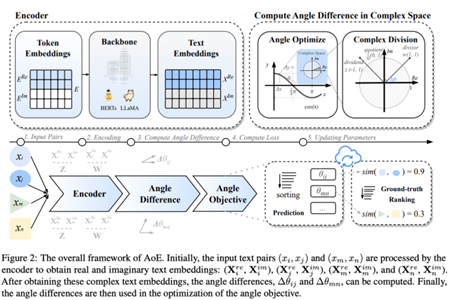
AnglE Framework: Angle-Optimized Embeddings in Complex Space for Enhanced Semantic Understanding
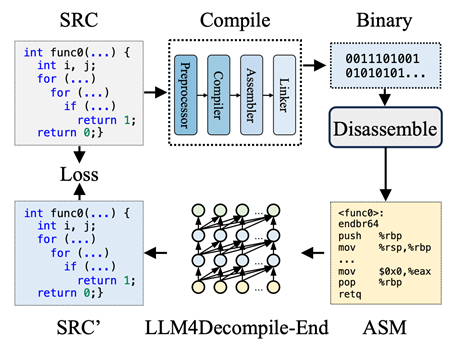
LLM4Decompile: Binary-to-Source Code Transformation using Large Language Models
LLM4Decompile: Decompiling Binary Code with Large Language Models
Decompilation, the task of converting binary code to high-level source code, is crucial for software analysis and reverse engineering—but traditional tools like Ghidra often produce decompiled results that are hard to read and execute. Driven by the rapid advancements in Large Language Models (LLMs), we propose LLM4Decompile, the first and largest open-source LLM series (with model sizes ranging from 1.3B to 33B parameters) fine-tuned on 15 billion tokens specifically for binary decompilation.
• 100%+ improvement over GPT-4o and Ghidra in re-executability
• 6K GitHub stars and featured in Weekly Trending
• 67 citations on Google Scholar